
This is the fifth in a series of blog posts I’ve been working on during COVID isolation. It started with the idea of refreshing my systems design and software engineering skills, and grew in the making of it.
Part 1 describes ‘the problem’. A mathematics game designed to help children understand factors and limits which represents the board game Ludo.
Part 2 takes you through the process I followed to break this problem down to understand the constraints and rules that players follow as a precursor to implementation design.
Part 3 shows how the building blocks for the design of the classes and methods are laid out in preparation for understanding each of the functions and attributes needed to encapsulate the game.
In Part 4 we get down to business… producing the game using the programming language PHP with an object orientated approach.
And now in Part 5 we step it up a notch and translate the code to object orientated C++. Read on!
Get in touch on Twitter at @mr_al if you’d like to chat.

C++
Available on GitHub at: https://github.com/mr-alistair/ootest-c-plus-plus
A short history of study and the Internet…
I took myself to University as a so-called ‘mature age student’ (I was 23 years old…so mature, so very mature…) and did night-classes for 5 ½ years to get my Bachelor degree in Computing.
By this stage I had been exposed to computers half my life, had self-taught myself BASIC and some COBOL, and had spent most of that half-life exposed to two extremes of computing. At one end were early self-contained personal computing systems (i.e. Sinclair, Commodore, Apple II, and what were then called ‘PC-compatible’, later known as Wintel systems (before Windows became a Thing)). At the other end were the big-end-of-town industrial strength mainframes (ICL, IBM) running VME and MVS respectively.

I was fortunate in my timing of arriving as a (“mature”) University freshman in 1995. This thing called the Internet was on the rise and was starting to break out of the confines of DARPA and education institutes and find it’s way into the world. As a result, my early studies of software engineering were through learning HTML and C. Not C++ … we heard about it later, of course – just C.
So, it was with this aging and basic understanding of the syntax and rules that I set about converting the object orientated version of what I now called ‘Auto120’ to C++.
Avoiding getting lost in translation
Following PHP, C++ struck me immediately due to its discipline. That there were syntactical similarities with PHP was pleasing to me. The self-referential use of ‘this’, the -> arrows to indicate properties within Classes, and the use of curly brackets, to name a few. The typing of variables – and having to explicitly identify an integer or a Boolean – meant taking a closer look at my code to avoid assumptions around how each variable would be treated.
A major difference between the two languages was needing to identify which general Class libraries to include in order to get what I would consider ‘basic’ methods to work. By this, I mean: strings, date/time methods and some array iterators. This took some trial and error, and a fair bit of time trawling Stackoverflow. (Praise be).
The Hit List
It was during my code migration from PHP to C++ that I realised that there was a recurring “hit list” of things were that were going to be different for each language. Once I had identified how to implement these, the rest would be easy* (*it wasn’t easy, I was just idealistic). They were:
- Instantiating an array of another Class
- Instantiating a two-dimensional array
- How strings and integers were parsed and concatenated into a longer string
- Generating random integer numbers
- FALSE, False, false and 0
- Setting iterative ranges
- Searching for a value in an array
- Copying an array (without creating an array of pointers to the original array)
These eight items became my prove-yourself entry-criteria that I set myself to ensure worked as I took on each subsequent language.
History, Part 2
Side story: There was a gentlemen who worked with me in various projects and departments at a few different companies. He was a software engineer, one of the best I’ve ever worked with. He was never happier than when he had his headphones on and a juicy set of technical problems to solve. You’d give him one problem to solve, and he’d return it to you, fixed, along with three other problems he’d found along the way that no-one had realised were there before. And as he walked back to his desk, he’d say: “Oh… and it runs about ten times faster now, too…”. No ego, no arrogance. Just a master craftsman in his prime.
One day, I asked him about career aspirations and the opportunity to become a manager. He recoiled at the idea. Not for him. Programming and software engineering were his things, and he was perfectly happy doing that. “You see”, he explained, “all programming is the same. They just change how they do something. I know how to program. The language doesn’t matter. Once you learn the basics, you can do any programming in any language.”
This from the guy who would take home a book on a particular language, read it overnight, and then churn out reams of bug free and efficient code the next day on a platform he’d never used before.
I thought, then, that he was an exception. Having now gone through this exercise with six different languages, I know now that he was right. It’s the same. The syntax and variations alter with the whim of the language designers, but the basics remain.
Coda: Notably, when I was at a company implementing the SAP ERP, I asked him how he was going learning the new platform. He smiled and said: “SAP… it is like it is a big house, with many rooms. And each room – ECC, SRM, CRM, etc. – has been decorated by a different person, with different wallpaper, carpet and furniture.”. This is a great analogy for any complex system that has been built or acquired in modules over time. As I often say in my corporate life, “The best thing about our standards is that we have so many to choose from…”.
Back to C++
Back in the 90’s (no, not the start of the BoJack Horseman closing theme… but try to get that out of your head, now) we cash-strapped under-grads had to fork out $89.95 for a “student edition” of Borland C++ which came in a neat box with a finely-printed manual and about 30 x 3 ½ “ floppy disks to install it. This was an ASCII/Text based GUI, with garishly coloured block graphics providing a workspace. Even back then, you could configure it for light mode, or dark mode. All the colour schemes were equally horrendous, so you chose the least-worst you could, and went from there.
Fast forward 25 years and you can download any number of decent IDEs for free, and don’t need to spend the next hour feeding in disk 24 of 30. For C++, I chose Microsoft’s Visual Studio Community Edition. This was to serve me for both my C++ and Python activities and suited my needs well. It’s also the tool I used to render the class diagrams shown in Part 3 of this series.
For about an hour I considered diving into building a GUI version of the Auto120 game. However, recent experience coding a GUI in Android had left me scarred, and my focus was on getting the code to work. So, I decided to save that for a later version, and continued with a console/text version.
As I worked through converting the code from PHP there were a few obstacles that I came up against. Most of these are highlighted in the eight key items mentioned earlier. But there was also the general syntax and expectations of the compiler to consider. My Android experience had dragged me into the 21st century in terms of what contemporary OO programming and IDEs looked like. So, the concept of a ‘smart’ IDE realising that I was attempting to reference a method that needed an ‘include’ and being able to resolve a run-time issue with a click of the mouse, was pleasing to me.
Pointers and types and dates, oh my
The trickiest thing was working through whether C++ was expecting an Object or variable to be referenced directly, or as a pointer. I’d never quite ‘got’ pointers in my undergraduate studies. I get them slightly more, now, but I don’t really want to.
C++ is more tightly-laced that PHP. It wanted to declare the return type of each Class. I needed to swap my TRUEs and FALSEs for 1s and 0s. I had to declare the size of an array, not just start populating one on a whim. C++ handles destructor classes differently… let’s just say it’s got an itchy trigger finger and has already starting flushing things that you may wish to call on the way out. Still trying to call that method during a destruction event? Nope, she gone.
Generating a time stamp was like going back to driving a stick shift after decades of driving an automatic. You want me to include a library for that? O…K… Integers and strings don’t naturally mix well – PHP was *very* forgiving in that regard – thus requiring a new level of concatenation and parsing.
But the thing that tripped me over time and time again were pointers, particularly when passing them to other Class methods. Trying to get the syntax right between the declaration and the function call-back did my head in. After a few nights of Googling and rewriting code, I realised that the problem lay in a combination of the Engineer (me), and his (my) understanding of the IDE.
Working with the tool, not against it
Modern IDEs try to help you out. You declare and instantiate something in code, and it believes that to be the canonical truth for any subsequent calls or references made to that. However, if you’ve got it wrong to begin with, it goes along with what it believes was your original intent. I realised this when, in frustration, I blew away a set of Class methods that had pointer-based declarations and rebuilt them with direct references. I built a new call in and different Class method that referenced this one, and it worked.
But none of the previous code which I’d written, which looked identical would compile or run.
Why? Because it was looking for a method interface that was from the original structure that had pointer references. It took walking through the code and re-typing each of those calls – and seeing the IDE pick up the references correctly – to get it to work. Sigh.
Stepping through the selected Hit List items
So – details of some C++ idiosyncrasies that varied my approach when compared to PHP:
- No native classes for what I would consider to be ‘basic’ object types – string, array search functions (begin / end / find) and methods for time calculation. The code needed me to include five additional head libraries (string, algorithm, iterator, cstdlib and ctime) to do what I wanted it to do, the way I’d written it.

- Needing to explicitly allocate space for an array when declaring. C++ wants you to be more disciplined in allocating such memory space. I found this by accident when wondering why my code appeared to be suddenly stopping mid-game. Turned out that I had exhausted the memory allocate for the std::string g_movelog[] array which I didn’t think would go beyond, say, 2000 records. Ah, no – it wanted me to declare the byte size. So, I declared it with a size of 1,000,000 and continued debugging.

- Similar issue with declaring arrays of a Class, in this case needing to hold two Player instances in the Game class Player g_players[]. After repeated null object errors, I finally changed the instantiation to read:
Player g_players[3] = { Player(0), Player(1), Player(2) };
- Searching for a string instance within an array was entertaining. This was needed for the method which searches for penultimate or factor Marker locations to avoid moving those pieces. C++ needed to know the start and end of the array reference as well as the location of the piece to avoid. BUT std::find will return a pointer to the space AFTER the last element (as std::end) in the array if it is not found.
So, the Boolean logic to find an instance of the returned Location of the Player’s piece within the array of x_temp_magic ended up being:
x_test_1 = std::find(std::begin(x_temp_magic_numbers), std::end(x_temp_magic_numbers), x_player.p_pieces[x_temp_value].m_get_location()) != std::end(x_temp_magic_numbers);
In other words, return a true value if you find the location between the beginning and end of array. However, if the find returns the std::end pointer, return a false, because it was not found.
That’s a few hours of my life that I’ll never get back.
Crazy random happenstance
When I finally got it to debug and run, I found a new issue. This is a game of chance and of mental arithmetic. However, after a few single runs I found an issue. The game ran to a valid conclusion in 155 moves. When I reran it, it did the same thing. 155 moves. Huh. Co-incidence? No. Third time, 155. The moves matched play for play. It was algorithmic Groundhog Day.
I’m a big fan of saying “computers only ever do what you tell them to do”. Meaning, the data you feed them, and how the engineer encodes an algorithm. In this case, I realised I was a victim of my own assumptions. As many will understand, ‘random’ numbers generated by a digital algorithm are rarely truly random. They use clever maths to produce an apparently random number, which fools most people into thinking it is, indeed, a number produced by chance.
It isn’t. This is why analogue systems out-perform digital systems in producing truly random numbers. (and even then, thanks to the beautifully written ‘Chaos’ by James Gleick, some analogue/natural patterns are far from random.). What fast-moving digital systems need is a variable seed.
So – the answer seemed simple – add a seed generator in the method ‘g_return_random’ which I’d added as a method to the Game class. So, I did, like so, after including the <random> library:
srand((unsigned int)time(NULL));
I recompiled and ran, and lo and behold, it worked! A random game. I ran it again, and it was different. Bingo.
But there was an issue. I was raised to believe that C++ was truly fast – epic fast compared to some modern languages, including PHP. So… why was my PHP code, running on a shared hosting platform with so many layers of infrastructure, network and software between it and me, blowing the C++ code out of the water?
Simple and obvious answer. What had changed? Every time the C++ code was generating a random number – which was every move plus often within moves as it decided amongst multiple Pieces to move – it was generating a new random seed based on the timestamp. This, it turns out, was like driving the algorithm with the handbrake on. It worked… but it chewed up a lot of CPU cycles doing it.
So, in the parent calling code (outside of the Game class and in the main() method of the program overall), I added a conditional after each Player’s move:
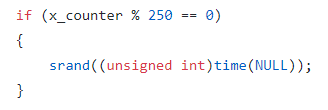
(where x_counter is the overarching looper attribute that stops the code running forever; the code terminates cleanly when it reaches 10,000 moves).
So – every 250 loops the random seed would regenerate, including when the code first ran.
After a few weeks I thought… but the average game was 155 moves before the seed was being set. How do we even know it’s getting to this point and changing the seed?
I inserted a debug line in the conditional which read:
cout << “%%% SEED FLIPPED %%%”;
…and piped the output. The result was obvious-in-retrospect. The modulus of 0 and 250 and is, of course, zero. So, the seed generation was occurring BEFORE the first move of the game. Given the rapidly changing value of ‘time’ (which is returned in milliseconds) it was sufficient to produce a random-enough seed that affected the rest of the game play. The repeat of the seeding at the 250 move mark would mean that any logical loops that had been inadvertently created in the game play would receive a ‘nudge’ that would set them on a new path.
C++ was done and dusted. It was time to move on to Java.
NEXT POST… Embracing the world of Java, with a different IDE and thinking… how hard can this be…?