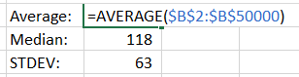This is the twelfth in a series of blog posts I’ve been working on during COVID isolation. It started with the idea of refreshing my systems design and software engineering skills, and grew in the making of it.
Part 1 describes ‘the problem’. A mathematics game designed to help children understand factors and limits which represents the board game Ludo.
Part 2 takes you through the process I followed to break this problem down to understand the constraints and rules that players follow as a precursor to implementation design.
Part 3 shows how the building blocks for the design of the classes and methods are laid out in preparation for understanding each of the functions and attributes needed to encapsulate the game.
In Part 4 we get down to business… producing the game using the programming language PHP with an object orientated approach.
Part 5 stepped it up a notch and walked through a translation of the code to object orientated C++.
Part 6 delves into the world of translating the code into object-orientated Java.
In Part 7 the same code is then translated into Javascript.
In Part 8 I slide into the sinuous world of Python and learn a thing or two about tidy coding as I go.
Part 9 explored the multi-faceted world of Ruby.
In Part 10 I started down the path of comparative analysis by asking the question – did all of these languages implement the algorithm consistently, and how would we know if they did?
This is continued in Part 11, with some weird stuff showing up when comparing the outputs of the coded algorithms side by side.
Get in touch on Twitter at @mr_al if you’d like to chat.

A Brief History of Randomness
As mentioned earlier, there were a few thoughts I had early in the game design and coding process which may explain the differences in results across parallel runs of the same algorithm in different languages. In the black box of each languages’ include files and libraries are a variety of methods for generating pseudo random numbers. There are several, often quite emotive, debates amongst mathematicians and software engineers as to how to generate a truly ‘random’ number.
Famously, the engineers at Cloudflare came up with a nifty solution derived from a patented idea by Silicon Graphics. This involved a physical implementation of a set of lava lamps, generating non-digital entropy which is then used to seed random number generation. My mind is drawn back to Douglas Adams’ description of the Infinite Improbability Drive from the Hitch Hikers’ novels, which used a strong Brownian motion producer (say, a nice hot cup of tea) as an alternative to a wall of lava lamps.
However, for the average software engineer, it is a black box. So, my next thought was that something had slipped into the code base – particularly when I was wrestling through the spacing and grammar markers that plagued me in Python – which had perverted the logic. Could an errant semi-colon or un-closed conditional mean that the code for Python and Ruby was ‘behaving’ differently to the earlier versions?
Code Walking
Time for a visual grep. You know what a ‘grep’ is, right? It is a ye olde and popular Unix/Linux command line utility for searching for pattern strings. Highly efficient and rich with options that have been tacked onto it over time. However, it’s only as good as the definition of what your looking for, and the structure of what you’re looking “in”.
When it comes to comparing code of different languages, things are a bit trickier. Yes, there are advanced search and replace style converters out there (some of which turn out some truly barbaric chunks of code, as witnessed during far-too-many Y2K code migrations). But sometimes, it’s easier to do a ‘visual grep’ – namely, print out both sets of code, and sit down with a glass of something Scottish and highly alcoholic, and go at it line by line, side by side.
Which I did.

I chose the C++ version and the Python version of the Game class, mainly as it is the most complex and also because it encapsulates almost all of the game flow logic.
There had been a few weeks between producing these blocks of code, and my struggles with debugging the Python code, which meant I was very familiar with it.
What I was looking for was obvious typos, omissions or lines of code which varied markedly from method to method. My hope was that, as the old techo joke goes, that the problem “existed between the keyboard and the chair”, and that a slip of the wrist had resulted in a change in the logic flow which was causing the Python code to run very differently. (The Ruby code was a transcription of the Python code, so my working assumption was that if a mistake had been made, that it would be in the Python.)
That assumption turned out to be unfounded. I did come across some redundant code in the C++ version, which doesn’t affect game play. However, the Python version was clean. I would have to look more closely as to why games played out through that language ‘took longer’ and produce different results than their earlier counterparts.
Looking for a Smoking Gun
Again, my suspicions fell on the pseudo-random number generation (or PRNG for those who enjoy a good acronym) engine type used by each language. Each language typically has a base/common PRNG algorithm it uses to generate numbers. These in turn use one of a handful of known and trusted mathematical formulae to produce output that looks ‘close enough’ to being random for most decisions. (‘Most’ generally excludes secure encryption.)
PHP’s own documentation on the random_int() function goes so far as to advise how different underpinning PRNG methods are applied depending on the platform:

That looks pretty good… but it wasn’t the default PRNG engine I’d used.
There are plenty of articles written about the use of PRNGs in simulation or gaming software. With the benefit of hindsight (and a lot of simulation runs) it now seems obvious that the formula behind the PRNG used in the C++, Java, Javascript (and probably PHP) code was the same. Ruby and Python are most likely using a formula with the intriguing name – “Mersenne Twister” – which, up to now, I’d taken to be some sort of burlesque dance move.
So, I took a version of the PHP code and went through it, replacing instances of rand() with mt_rand(). I re-ran the 49,999-run test… and the results were pretty similar to the original run.
Why? Turns out that from PHP 7.1 the code for array_rand was changed to use – you guessed it – the Mersenne Twister formula.

Outside of dice rolls, choosing a element from an array is the most-used random selection that the Auto120 game goes through. So – what if the PHP version was rolled back (along with the use of mt_rand) and the code re-run? That was next.
The Difference between Data Science and Data Analysis
I’ve been around a while. Not as long as some, but long enough to see the repeating patterns that emerge over time when it comes to Information Technology. They keep coming, too. The ‘cloud’ of today is the ‘outsourcing’ of the 90s. the “Big Data” of today is the “BI” of the 00’s. And so on. Everything’s stolen, nowadays.

There are a lot of people around who use the term ‘data science’ without understanding what it really means. It’s a pretty simple thing to consider, and those who publish on the subject argue that it is either: another name for statistics, or is not… takes into account qualitative observations, or does not… and so on.
I’m reminded of two of my favourite paradigms – one being the parable of the Blind Men and the Elephant (TL/DR: each individual, having never actually ‘seen’ an elephant, opines a strongly held opinion about what an elephant is based on a single point of data), and Niels Bohr’s reuse of an old Danish proverb “Det er vanskeligt at spaa, især naar det gælder Fremtiden” that roughly translates as: “Prediction is difficult, especially about the future”.
To whit, analysing data can tell us “what happened” but rarely tells us, precisely, what is “going to happen”.
Science is a simple discipline, made difficult by the complexities of the subject matter. The joy of marrying the words “data” and “science” is that you get a self-explanatory statement. (Despite that, I’ll explain.) The scientific method begins with making a conjecture – a hypothesis – and then designing, executing and recording the results from repeatable experiments which provide the evidence that prove this hypothesis through predictable results.
This is what I was attempting to do with developing the broader framework of the Auto120 game. Being – if you design and build an instance of an algorithm you SHOULD get repeatably consistent results in the output REGARDLESS of the language it is implemented in.
Well. Let’s break that down.
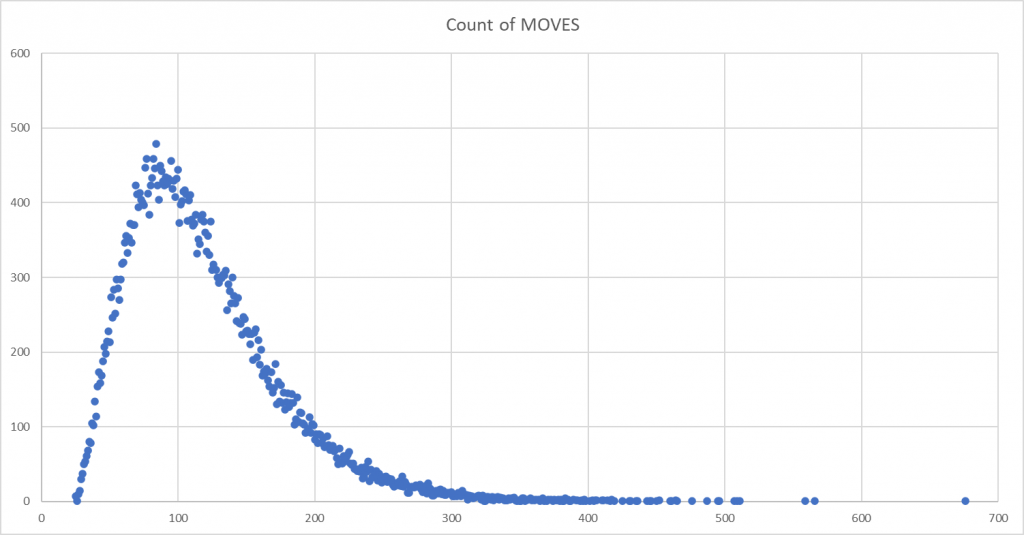
Yes, the results are consistent… but not as consistent as I would have expected. Yes, they are generally consistent across different languages. But, they’re not precisely the same. Like the wobble in Uranus’ orbit which led astronomers to discover the planet Neptune, there is something ‘different’ between two subsets of languages – with Python and Ruby in one camp, and PHP, C++, Java and Javascript in the other. And even PHP is slightly skewed.
Back to Random
So, my working hypothesis was this – the random number generator in use by PHP – being either the original algorithm or the Mersenne Twister version – could cause the data to skew. To test, the further experiment was this – 1) run a version of the 49,999 run on PHP 7.0, which pre-dated the integration of the Mersenne Twister, and 2) run a version of the 49,999 on PHP 5.6, AND replace the use of the array_rand method with a random integer selection instead.
My expectation was to see four different looking sets of data, including the original run and the follow up run where I’d substituted rand_mt.
The reality was this:

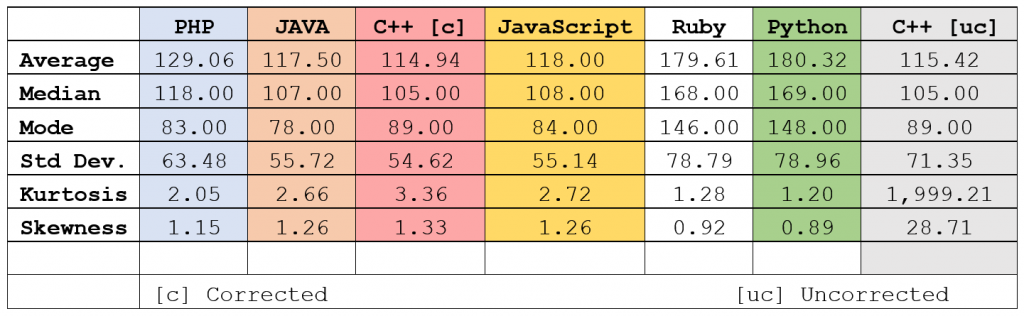
Yep. They’re the same. Almost. Look in the table below at the MODE for the two runs that DON’T use the Mersenne Twister for random number generation:
| PHP | PHP-MT | PHP-5.6 | PHP-7 | Standard Deviation (of the PHP runs) | |
| Average | 129.06 | 128.83 | 128.99 | 129.58 | 0.33 |
| Median | 118.00 | 117.00 | 117.00 | 118.00 | 0.58 |
| Mode | 83.00 | 86.00 | 102.00 | 103.00 | 10.47 |
| STDEV | 63.48 | 63.75 | 63.40 | 63.64 | 0.15 |
| Kurtosis | 2.05 | 1.90 | 2.02 | 1.95 | 0.07 |
| Skewness | 1.15 | 1.14 | 1.15 | 1.14 | 0.01 |
The Mode, the most frequently occurring move count, is 20 moves MORE than the other runs. (But, still, 40 moves FEWER than for Ruby and Python.)
So, the random number engine did play a part. But did it play such a significant part as to impact the Python and Ruby results the way they did? It was time to run another test to find out.
Next post… having ruled out the random number engine as the significant contribution to different languages’ game behaviour, it was time to deep dive into what may have changed in the code…